kroller : a tiny (restart) tool to help for kubernetes cluster upgrade
Kubernetes upgrades (especially EKS) are categorized into two types based on the Kubernetes architecture:
- Control plane upgrade (+ etcd)
- Node upgrade
Particularly when using cloud-managed Kubernetes like EKS, since AWS manages the control plane, you’ll mostly handle node upgrades directly (if you’re not using managed nodegroups).
When you upgrade the control plane, you’ll have nodes with different versions of kubelet as shown in the diagram below:
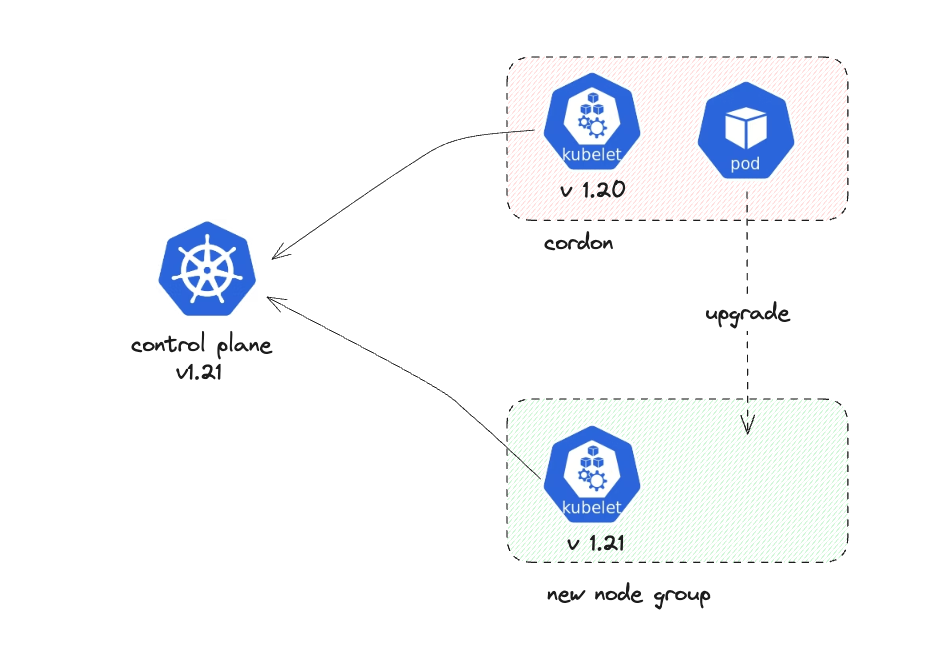
For clusters that are not large-scale, you would typically create a new node group of the same size as the current one and relocate pods from the previous node group to the newly created node group (temporarily maintaining twice the number of nodes).
In this case, you need an efficient way to relocate all applications. But what exactly is relocation? Despite its name, is it any different from a regular deployment?
Approaching exceptional situations as normal ones helps prevent many problems. In reality, although we call it relocation, it’s not much different from a regular deployment except that the purpose is relocation.
However, since it’s inconvenient to relocate (redeploy, restart) hundreds of applications at once, I wrote a simple CLI for a kind of simple automation.
$ kroller -h
USAGE
kroller <subcommand>
SUBCOMMANDS
restart restart all rollout resources
drain drain node
show show details of nodes or resources
version show version of kroller
FLAGS
-kubeconfig ... kubeconfig file
-v false log verbose output
Looking at the list of subcommands, first there’s a command called restart.
$ kroller restart -h
USAGE
restart all rollout resources (deployment,statefulset)
FLAGS
-config ... config file (optional)
-kubeconfig ... kubeconfig file
-target ... only use the specified objects (Format: <namespace>/<type>/<name>)
-v false log verbose output
The most interesting flag is -target.
-target ... only use the specified objects (Format: <namespace>/<type>/<name>)
As a cluster grows over time and includes many Kubernetes objects, you might need to operate on only a subset of them (e.g., apply to only certain applications).
The -target flag provides the ability to limit which objects to restart. (Format: <namespace>/<type>/<name>) Especially since it supports RE2, you can use all kinds of wildcards and other advanced matching features to select Kubernetes objects.
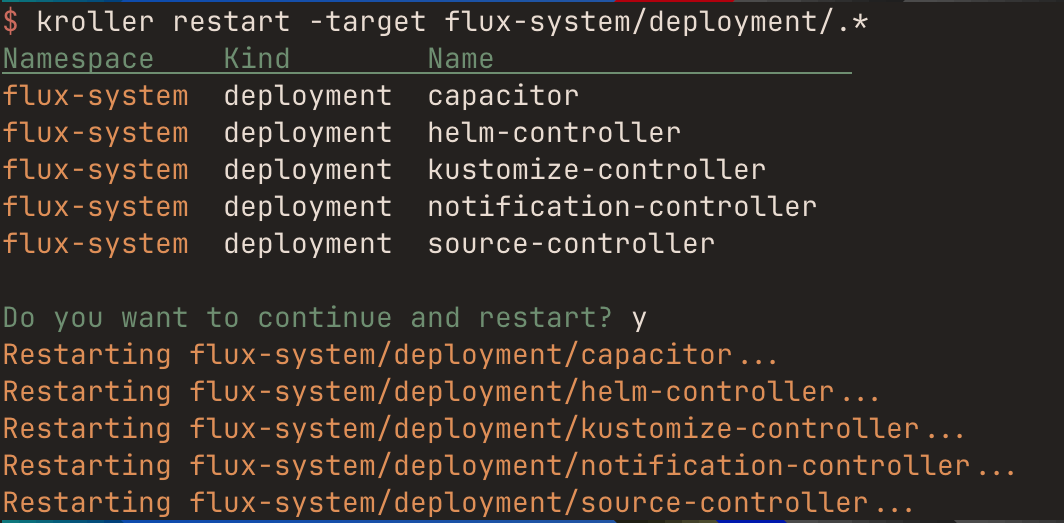
The format and structure of this flag is borrowed from Output filtering | Grafana Tanka.
Next is the -config flag. It’s not common to restart all applications at once; instead, you’d typically perform a phased operation. For example, you might distinguish between service applications and addons (e.g., ingress, etc.) for staged redeployment.
In such cases, rather than writing -target each time, you write a config file and run it.
# flux-system.cfg
target flux-system/deployment/.*
v
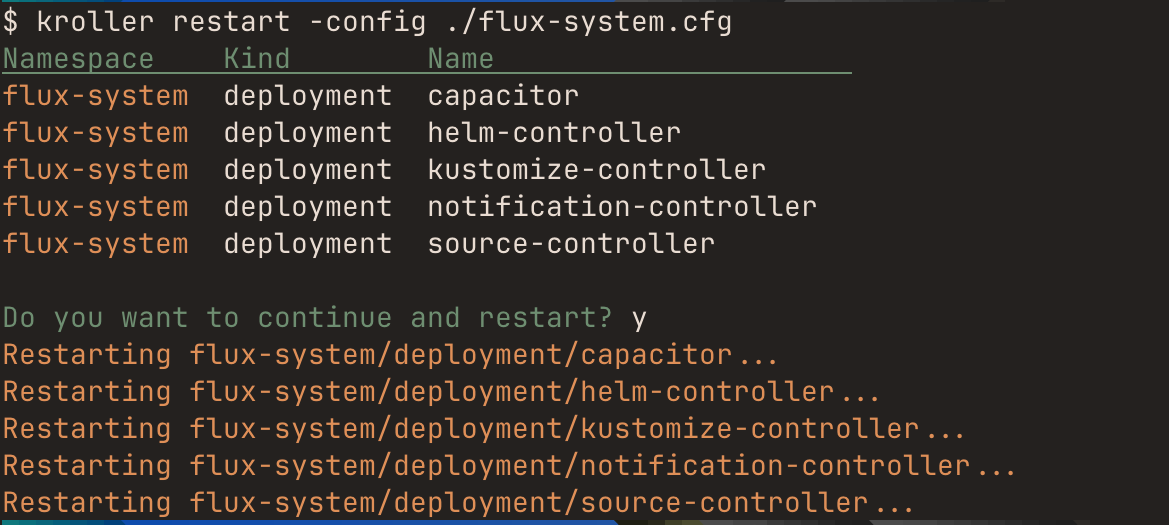
The config file is simply writing the flags for kroller restart to a file. So not just -target but other flags can be written to the config file as well.
There are also features like kroller show nodes to check nodes and pods.